

基于深度学习的方法已经广泛用于工业推荐系统(RSs)。以前的工作通常采用嵌入(Embedding)和 MLP 范式:原始特征嵌入到低维向量中,然后将其输入 MLP 以获得最终的推荐结果。 然而,这些工作中的大多数只是连接不同的特征,忽略了用户行为的连续性。近日,阿里巴巴搜索推荐事业部发布了一项新研究,首次使用强大的 Transformer 模型捕获用户行为序列的序列信号,供电子商务场景的推荐系统使用。该模型已经部署在淘宝线上,实验结果表明,与两个基准线对比,在线点击率(CTR)均有显著提高。本文是 AI 前线第 79 篇论文导读,我们将对这项研究工作进行详细解读。
论文作者系阿里巴巴 Qiwei Chen、Huan Zhao、Wei Li、Pipei Huang、Wenwu Ou,由 AI 前线编译整理
论文原文链接:https://arxiv.org/pdf/1905.06874.pdf
介绍
推荐系统(RSs)已经在工业界流行了十来年,在过去五年里,基于深度学习的方法在工业界得到了广泛应用,例如,Google 的 wide & deep 模型和 Airbnb 的《Real-time personalization using embeddings for search ranking》。在阿里电商平台,RSs 已经成为 GMV 和收入的关键引擎,并在丰富的电子商务场景中部署各种基于深度学习的推荐方法。RSs 在阿里巴巴分为两个阶段:匹配(match)和排名(rank)。在匹配阶段,根据用户和商品的交互,一些相似的商品被选择出来作为候选集,然后学习一个 fine-tuned 预测模型,来预测用户点击给定候选商品集的概率。
在本文中,我们关注的是阿里巴巴淘宝的排名(rank)阶段。在阿里电商平台有数百万候选商品,我们需要根据用户的历史行为,预测他/她点击给定候选商品的概率。在深度学习时代,嵌入和 MLP 已经成为工业 RSs 的标准范式:大量的原始特征嵌入到低维空间中作为向量,然后输入到全连接层,即多层感知机(MLP),以预测用户是否会点击某个商品。其代表工作是 Google 的 wide&deep 网络(WDL)和阿里巴巴的深度兴趣网络(DIN)。
在淘宝,我们基于 WDL 网络构建 rank 模型,其中各种特征都使用 Embedding 和 MLP 范式,比如,商品的类别和品牌特征、商品的统计特征、用户画像特征。尽管这一框架取得了成功,从本质上讲,它远不能令人满意,因为它在实践中忽略了一种非常重要的信号,即用户行为序列背后的序列信号,即用户按顺序点击商品。实际上,该顺序对于预测用户的未来点击非常重要。例如,用户在淘宝买了一部 iPhone 后,往往会点击手机外壳,或者在买了一条裤子后试图找到合适的鞋子。从这个意义上来说,在淘宝排名阶段部署一个预测模型时,不考虑这个因素是有问题的。在 WDL 中,它仅仅是连接所有特征,而没有捕获用户行为序列之间的顺序信息。DIN 提出使用注意力机制来捕获候选项与用户先前点击商品之间的相似性,但未考虑用户行为序列背后的序列性质。
因此,在这项工作中,为了解决 WDL 和 DIN 面临的上述问题,我们尝试将淘宝上的用户行为序列的顺序信号整合到 RS 中。受自然语言处理(NLP)中机器翻译任务 Transformer 大获成功的启发,通过考虑嵌入阶段的顺序信息,我们运用了 self-attention 机制,在用户行为序列中,为每个商品学习一个更好的表征。然后,将它们输入 MLP,以预测用户对候选商品的反馈。
Transformer 的主要优点是,它能更好地捕获句子中单词之间的依赖性,通过 self-attention 机制,直观地说,用户行为序列中 item 之间的“依赖关系”可以通过 Transformer 抽取。因此,我们提出了在淘宝电商推荐中的用户行为序列 Transformer(BST)。离线实验和在线 A/B 测试表明,BST 与现有方法相比有明显优势。目前 BST 已经部署在淘宝推荐的 rank 阶段,每天为数亿消费者提供推荐服务。
本文第 2 节将详细阐述 BST 的体系结构,第 3 节介绍包括离线和在线测试的实验结果。相关工作在第 4 节中进行了回顾,最后是我们对这项工作的总结。
架构
在 rank 阶段,我们将推荐任务建模为点击率(CTR)预测问题,定义如下:给定用户的行为序列 S(u) = {v1,v2, …,vn } 被用户 u 点击,我们需要学习一个函数 F 来预测用户点击 vt 的概率,其中 vt 是其中的一个候选 item。其他特征包括用户画像、上下文、item 和交叉特征。
我们在 WDL 之上构建 BST,总体架构如图 1 所示。从图 1 中,我们可以看到它遵循流行的 Embedding&MLP 范式,其中,先前的点击 item 和相关的特征首先嵌入到低维向量中,然后再输入到 MLP。BST 和 WDL 之间的关键区别在于我们添加了 Transformer 层,通过捕获底层的顺序信号来学习更好地表征用户点击的 item。在下面的部分中,我们自下而上地介绍了 BST 的关键组件:Embedding 层、Transformer 层和 MLP。

图 1 BST 的总体架构
BST 将用户的行为序列作为输入,包括目标 item 和其他特征。它首先将这些输入特征嵌入为低维向量。为了更好地捕获行为序列中 item 之间的关系,Transformer 层用于学习序列中每个 item 的更深层次的表示。然后通过连接其他特征的嵌入和 Transformer 层的输出,三层的 MLP 用于学习隐藏特征的交互作用,Sigmoid 函数用于生成最终的输出。
注:“位置特征”被纳入了“序列特征”。
2.1 Embedding 层
第一个组件是 Embedding 层,它将所有输入特征嵌入到固定大小的低维向量中。在我们的场景中,有各种各样的特征,比如,用户画像特征、item 特征、上下文特征以及各种不同的组合特征。由于这项工作的重点是用 Transformer 建模行为序列,为了简单起见,我们将所有这些特征表示为“其他特征”,并在表 1 中给出一些示例。如前面图 1 所示,我们将左侧的“其他特征”连接起来,并将它们嵌入到低维向量中。对于这些特征,我们创建了一个嵌入矩阵 Wo∈ R(|D |×do),其中 do 是维度大小。

此外,我们还获得了行为序列中每个项目的嵌入,包括目标 item。如前面图 1 所示,我们使用两种类型的特征来表征一个 item,“序列 item 特征”(红色部分)和“位置特征”(深蓝色)。其中,“序列 item 特征”包括 item_id 和 category_id。
请注意,一个 item 往往有数百个特征,但是,在行为序列中选择全部来表征这个 item 太昂贵了。正如我们之前的工作《Billion-scale commodity embedding for e-commerce recommendation in alibaba》介绍,item_id 和 category_id 对于性能来说已经足够好了。
在嵌入用户行为序列中,我们选择这两个作为稀疏特征来表征每个 item。“位置特征”对应于下面的“位置嵌入”。然后,对于每个 item,我们将序列特征与位置特征相结合,生成嵌入矩阵 Wv ∈ R(|V |×dv),其中,dv 为嵌入的维度大小,|V |为 item 的数量。我们使用 ei ∈ R(dv) 来表征给定行为序列中第 i 个 item 的嵌入。
位置嵌入:在《Attention is all you need》论文中,作者提出了一种位置嵌入来捕获句子中的顺序信息。同样,顺序也存在于用户的行为序列中。因此,我们添加“位置”作为 bottom layer 中每个 item 的输入特征,然后将其投射为低维向量。注意,item vi 的位置值计算为 pos(vi)=t(vt)-t(vi),其中,t(vt)表示推荐的时刻,t(vi)表示用户点击 item vi 时的时间戳。我们采用这种方法是因为在我们的场景中,它优于《Attention is all you need》论文中使用的 sin 和 cos 函数。
2.2 Transformer 层
Transformer 层通过捕获与行为序列中其他 item 的关系,为每个 item 学习更深入的表征。
Self-attention layer
scaled 点积 attention 在论文《Attention is all you need》定义如下:
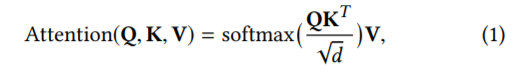
其中,Q 表示查询,K 表示键,V 表示值。在我们的场景中,self-attention 操作将 item 的嵌入作为输入,并通过线性投影将它们转换为三个矩阵,并将它们输入到 attention 层。跟论文《Attention is all you need》一样,我们使用 multi-head attention :

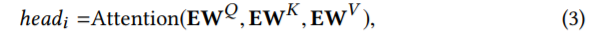
其中,投影矩阵 W(Q)、 W(K) 、 W(V) ∈ R(d×d) ,E 是嵌入所有 item 的矩阵。h 是 head 的数量。
#### Point-wise Feed-Forward Network
在论文《Attention is all you need》基础上,我们添加了 point-wise Feed-Forward Network (FFN),以进一步增强模型的非线性能力,定义如下:

为了避免过拟合,并从层次上学习有意义的特征,我们在 self-attention 和 FFN 中都使用了 dropout 和 LeakyReLU。
self-attention 和 FFN 层的整体输出如下:

其中,W(1)、b(1)、 W(2)、 b(2)都是可学习的参数,和 LayerNorm 层是标准的归一化层。
堆叠 self-attention 块
在 self-attention 之后,它聚合了之前所有 item 的嵌入。为了进一步建模 item 序列基础上的复杂关系,我们将自构建块堆叠起来,第 b 个块的定义如下:
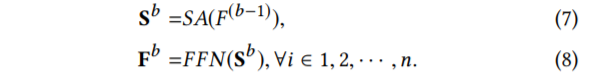
在实践中,我们在实验中观察到与 b=2,3 相比 b=1 获得了更好的性能(见下文表 4)。为了效率,我们没有尝试更大的 b,这部分工作将在接下来进一步研究。
2.3 MLP 层和损失函数
通过连接其他特征的嵌入和应用于目标 item 的 Transformer 层的输出,我们使用三个完全连接的层来进一步学习稠密特征之间的交叉,这是在工业界的标准实践。
为了预测用户是否点击目标 item vt,我们将其建模为一个二元分类问题,使用 sigmoid 函数作为输出单元。为了训练这个模型,我们使用了交叉熵(cross-entropy)损失函数:

其中,D 代表所有样本,y ∈ {0, 1}为标签表示用户是否点击了某个 item,p(x)是经过 sigmoid 单元之后的网络输出的概率值,表示样本 x 被点击的预测概率。
实验
3.1 设置
数据集
数据集是根据淘宝 App 的日志构建的。我们根据用户 8 天内的行为构建了一个离线数据集。我们使用前七天作为训练集,最后一天作为测试集。数据集的统计数据如表 2 所示。我们可以看到数据集非常大并且稀疏。

基准线
为了说明 BST 的有效性,我们将其与两个模型进行比较:WDL 和 DIN。此外,我们还通过将顺序信息整合到 WDL 中创建一个基准,称为 WDL(+Seq),它平均聚合以前点击的 item 的嵌入。我们的框架是建立在 WDL 之上的,通过添加 Transformer 的顺序建模,而 DIN 被提出是由于用 attention 机制捕获目标 item 和先前点击的 item 之间的相识性。
评价指标
对于离线结果,我们使用 AUC 评分用于评估不同模型的性能。对于在线 A/B 测试,我们使用 CTR 和 average RT 评估所有的模型。RT 是响应时间的缩写,表示给定查询生成推荐结果的耗时。我们使用平均 RT 作为度量标准来评估不同在线生产环境下的效率。
配置
我们的模型是用 Python 2.7 和 TensorFlow 1.4 实现的,并选择“Adagrad” 作为优化器。此外,我们在表 3 中给出了模型参数的详细信息。

3.2 结果分析
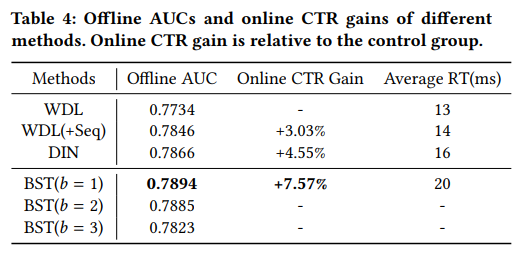
结果如表 4 所示,从中我们可以看到 BST 相对基准线的优势。
具体来说,离线实验的 AUC 由 0.7734(WDL)和 0.7866(DIN) 提高到 0.7894(BST)。当比较 WDL 和 WDL(+Seq)时,我们可以看到,以简单的平均方式整合顺序信息的有效性。这意味着在 self-attention 的帮助下,BST 提供了一种强大的能力来捕获用户行为序列的顺序信号。请注意,从我们的实践经验来看,即使是线下 AUC 的微小收益也会导致在线 CTR 的巨大收益。在 WDL 中,Google 的研究人员也报告了类似的现象。
此外,在效率方面,BST 的平均 RT 接近 WDL 和 DIN 的平均 RT,这保证了在现实推荐场景中大规模部署像 Transformer 这样的复杂模型的可行性。
最后,我们还展示了堆叠 self-attention 层的影响。从表 4 可以看出,b=1 得到最佳的离线 AUC。这可能是由于用户行为序列中的顺序依赖性不如机器翻译任务中句子复杂,因此,少量的块数量,就足以获得良好的性能。类似的观察报告见《Self-attentive sequential recommendation》论文。因此,我们选择 b=1 在生产环境中部署 BST,只报告了表 4 中 b=1 的在线 CTR 的收益。
相关工作
自从 WDL 提出以来,业界研究同仁提出了一系列以深度学习为基础的方法,如 Deepfm、Xdeepfm、Deep&Cross 网络等。但是,所有这些之前的工作都集中在神经网络的特征组合和不同架构,忽略了实际推荐场景中用户行为序列的顺序性。2017 年,阿里妈妈的精准定向检索及基础算法团队提出了深度兴趣网络 DIN,通过注意力机制来处理用户的行为序列。
我们的模型和 DIN 的关键区别在于,我们提出使用 Transformer 来学习用户行为序列中每个 item 的更深层的表征,而 DIN 试图捕获之前点击的 item 和目标 item 之间的不同相似性。换句话说,我们的 Transformer 模型更适合捕获顺序信号。在《Self-attentive sequential recommendation》论文和《Sequential Recommendation with Bidirectional Encoder Representations from Transformer》论文中,提出 Transformer 来解决顺序推荐问题,同时在 CTR 预测方面,体系结构方面不同于我们的模型。
结论
在本文中,我们介绍了如何将 Transformer 应用到淘宝推荐中的技术细节。利用强大的序列关系捕获能力,通过大量的实验证明了该 Transformer 在用户行为序列建模中的优越性。此外,我们还介绍了在淘宝生产环境中部署该模型的细节,目前 BST 已经在淘宝线上为中国数亿用户提供推荐服务。
更多内容,请关注 AI 前线


暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论